No ho sabeu, però esteu ajudant a digitalitzar els llibres antics!
Autor de la fitxa :
Hélène Laxenaire - SupAgro Florac
Llicència de la fitxa :
Creative Commons BY-SA
Testimoniatge :
Gràcies a reCaptcha, un projecte creat per la universitat americana Carnegie-Mellon, cada cop que us torneu mig guenyos per desencriptar un d'aquells textos retorçats, per acceptar una inscripció o enviar un comentari, esteu participant a la millora d'un programa de digitalització de llibres antics.
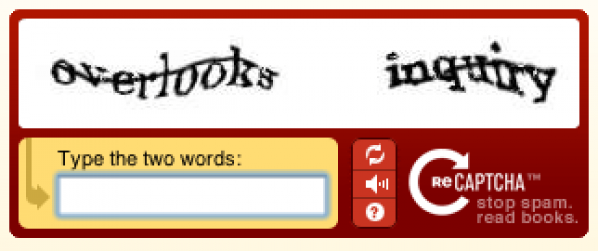
Quan se us demana que demostreu que sou un ésser humà i no una màquina mitjançant un reCaptcha, sempre hi ha 2 paraules, una de més deformada que les altres. Una ja ha estat identificada amb certesa amb el programari OCR (és la que serveix de manera efectiva per demostrar que sou un humà) i l'altra no (és la que ajudareu a identificar). A partir del moment en què un nombre determinat d'internautes han identificat de la mateixa manera una paraula sospitosa, és declarada vàlida. És integrada a la base de dades de les paraules validades de reCaptcha i a la base de dades que el programari d'OCR utilitza per reconèixer els caràcters dels llibres digitalitzats. Actualment el programari de reconeixement de caràcters de reCapcha ha aconseguit un nivell d'error similar al de l'ésser humà.
Tornem a començar des del principi: què són els captchas?
Els captchas són aquestes paraules completament deformades que us demanen que copieu per tal d'acceptar una inscripció o una acció en un lloc internet. El principi del captcha consisteix en trobar una operació més fàcil d'efectuar per a un ésser humà que per a un robot, per tal d'evitar que l'acció que esteu fent pugui ser efectuada automàticament mitjançant programes-robots. Sobretot per evitar que es puguin crear automàticament milers de comptes de correu o de Facebook o inundar un blog amb comentaris per tal de vendre fals Viagra. Tornant a picar el text deformat, esteu demostrant que sou un ésser humà (només des d'un punt de vista biològic, eh?)El problema de la digitalització dels llibres antics
Els llibres antics que ja han passat a ser de domini públic es podrien posar a l'abast de tothom per internet però per facilitar la recerca dins d'aquestes obres cal transformar la pàgina escanejada (que és una fotografia) en un text digitalitzat en el qual es pot fer una recerca. D'això se n'encarreguen els programaris de reconeixement òptic de caràcters (OCR), però amb aquestes obres es troben amb unes dificultats especials. De fet, estan impresos amb uns caràcters tipogràfics especials i sovint el temps n'ha fet malbé les pàgines. Per millorar l'índex de reconeixement, els programaris de reconeixement òptic de caràcters (OCR) necessiten "aprendre". És a dir que cal que els resultats que obtenen siguin confrontats amb els resultats obtinguts per humans per augmentar poc a poc el nombre de signes que poden reconèixer. Però per als humans, la feina de transcripció resulta llarga i feixuga.I si féssim que les coses útils... encara ho fossin més?
Luis Van Ham és professor a la universitat Carnegie-Mellon a Pittsburgh i treballa en human computation, és a dir en programaris que fan intervenir el poder de raonament humà i la velocitat de càlcul dels ordinadors per a resoldre problemes que ni els humans ni les màquines podrien resoldre sols (el cas dels programaris OCR n'és un exemple típic). Ha desenvolupat el concepte de jocs amb objectius, en el quals els éssers humans efectuen operacions útils tot jugant. Encara que no es tracti d'un joc, el reCaptcha es basa en aquest principi. Cada vegada que descodifiqueu una paraula deformada, extreta de la digitalització de llibres antics per demostrar al lloc internet que sou un humà, esteu augmentant la base de dades utilitzada pels programaris de reconeixement òptic de caràcters i per tant la seva eficàcia per reconèixer els caràcters digitalitzats dels llibres antics.Com funciona reCaptcha?
Les imatges escanejades dels llibres antics són llegides per dos programaris diferents de reconeixement de caràcters. Quan una paraula és llegida de manera diferent pels dos programaris, és considerada sospitosa i s'afegeix a la base de reCaptcha .Quan se us demana que demostreu que sou un ésser humà i no una màquina mitjançant un reCaptcha, sempre hi ha 2 paraules, una de més deformada que les altres. Una ja ha estat identificada amb certesa amb el programari OCR (és la que serveix de manera efectiva per demostrar que sou un humà) i l'altra no (és la que ajudareu a identificar). A partir del moment en què un nombre determinat d'internautes han identificat de la mateixa manera una paraula sospitosa, és declarada vàlida. És integrada a la base de dades de les paraules validades de reCaptcha i a la base de dades que el programari d'OCR utilitza per reconèixer els caràcters dels llibres digitalitzats. Actualment el programari de reconeixement de caràcters de reCapcha ha aconseguit un nivell d'error similar al de l'ésser humà.
Aleshores, és una bona obra?
Google va comprar reCaptcha el 2009 i el va instal·lar a les seves pàgines que requereixen aquest tipus de confirmació. El poder de Google ha donat molta visibilitat al projecte i n'ha augmentat el nombre de participants. El principal objectiu de Google és digitalitzar els llibres de Google books per tal de facilitar-ne el posicionament i possibilitar la recerca de text en aquestes pàgines. Però sembla ser que Google adapta reCaptcha a d'altres projectes i en alguns reCapcha s'han pogut reconèixer números de plaques de carrers que provenien de Google Street View.
Enllaç d'Internet :
http://www.google.com/recaptcha
