You may not know it, but you are helping to digitalise old books!
Card's author :
Hélène Laxenaire - SupAgro Florac
Card's type of licence :
Creative Commons BY-SA
Testimonies :
Thanks to reCaptcha, a project created by the Carnegie-Mellon University, every time you screw up your eyes while trying to decipher a twisted text to validate an entry or post a comment, you are actually contributing to improve a programme to digitalise old books.
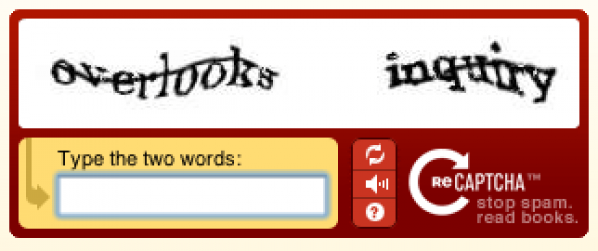
When you are asked to prove that you are human and not a machine using a reCaptcha, there are always two words, one is more deformed than the other. One of the two has already been identified as valid by OCR software (and this is the one used to verify that you are human) and the other one has not (this will be the word you help to identify). When a certain number of internet users identify a suspicious word in the same way it is then validated. It is then included into the database of validated reCaptcha words and into the database used by OCR software to recognise the characters in digitalised books. Today, the reCaptcha character recognition software has achieved a level of error similar to that of a human being.
Going back to the start: what are captchas?
Captchas are deformed words that you are required to re-copy to validate and entry or for an action on the Internet. The principle behind captchas is finding an action that is easier for humans than for robots, so as to avoid the action you are doing to be done automatically (using robot-software). Especially to avoid millions of email accounts or Facebook accounts from being created automatically or to avoid a blog being flooded in comments to sell false Viagra. By re-copying the deformed text, you are proving that you are a human being (only from a biological point of view though!)The issue of digitalising old books
Old books that are in the public domain could easily be made available to a larger audience on the Internet; however, to facilitate the search for these books, it becomes necessary to process a page scan (which is actually a photocopy) into digital text where searches can be made. Optical Character Recognition (OCR) software is in charge of this, but very often this software has many problems with this type of books. To improve their recognition rate, optical character recognition software programmes need to "learn". This means that their results must be compared to the results obtained by humans to gradually increase the number of characters they are able to recognise. However, transcription by humans is a long and repetitive task.What if we joined the tool to ... the tool?
Luis Van Ham is a professor at the Carnegie-Mellon University in Pittsburgh and he works on human computation, meaning programmes that combine the power of human thinking with the calculation speed of computers to solve problems that humans or computers alone cannot solve (OCR tools are a typical example). He developed the concept of objective games, whereby humans while playing, are actually carrying out useful operations. Even if it is not a game, the reCaptcha he developed follows this principle. Every time we decipher deformed words, taken from the digitalisation of old books, to prove to the internet site that you are a human being, you are actually contributing to the growth of the database used by OCR software and to improve their effectiveness in recognising digital characters in old books.reCaptcha, how does it work?
Scans of old book pages are read by two different types of character recognition software. When a same word is read differently by these two software programmes, it is considered suspicious and is added to the reCaptcha database.When you are asked to prove that you are human and not a machine using a reCaptcha, there are always two words, one is more deformed than the other. One of the two has already been identified as valid by OCR software (and this is the one used to verify that you are human) and the other one has not (this will be the word you help to identify). When a certain number of internet users identify a suspicious word in the same way it is then validated. It is then included into the database of validated reCaptcha words and into the database used by OCR software to recognise the characters in digitalised books. Today, the reCaptcha character recognition software has achieved a level of error similar to that of a human being.
Is this work positive?
Google purchased reCaptcha in 2009 and installed it on its pages asking for this type of validation. Given the power of Google, this has given a large visibility to the project and a larger number of participants. Google's main goal is to digitalise Google books and make it easier to refer to and search text in their pages. However, it would seem that Google has adapted reCaptcha to other projects; in this sense, some reCaptchas appeared containing street names from Google Street View.
Internet link :
http://www.google.com/recaptcha
